Microservices Architecture: Asynchronous Communication is Better


In recent years there’s been a lot of talk about microservices architecture. Switching from a monolithic architecture to a microservices based architecture is a complicated step that requires rethinking many aspects of development, testing, and deployment. One of the most important aspects of software architecture is communication. How do we pass messages between components? In a monolithic architecture that’s straightforward: everything is written in the same language and we can simply call methods to execute some logic on our data. In a microservices architecture this, like many other things, it’s not as straightforward.
There are many communication protocols but for web applications… this blog looks at why you should favor asynchronous in all cases. #SysAidtech #Tech Share on XTypes of communication
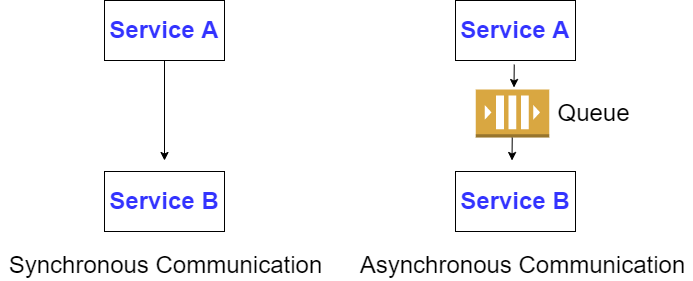
Generally speaking there are two types of communication: synchronous and asynchronous. You either want to have a reply, or you don’t. With synchronous communication the caller sends a message and waits for the receiver to respond. This is appropriate for actions such as login and purchase, in which the caller must have a reply. With asynchronous communication the caller skips the wait and continues executing whatever code is necessary. So, for example, in many cases changing settings is not something the caller would want to wait on.
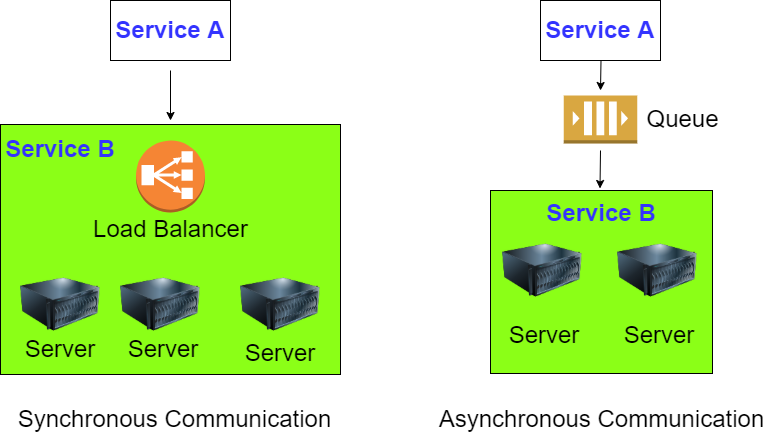
There are many communication protocols but for web applications the mainstream application level protocols are HTTP/S for synchronous communication and AMQP for asynchronous. Given that most sufficiently complicated applications have a need for both synchronous and asynchronous communication it’d make sense to employ both methods. But what if I told you that you should favor asynchronous in all cases? Talk to the hand you say? Trust me, there’s a method to my madness.
Pros
Let’s be optimistic and first go over the pros. They can all be put under a one word umbrella: separation. Everyone loves separation (in software, not in relationships obviously). Putting a queue between all our services makes them completely anonymous to each other. So if our web service wants to generate a report it sends a message to a queue saying it wants a report. It doesn’t know which service is handling it, if it’s up or what version it is. It expects that, given the message it’s sending, a report will be generated, but it doesn’t know the URL, IP, or port of the report generation service, nor does it know which protocol it uses to communicate.
Scalability
Now let’s say we send a lot of report generation requests and they take a long time to process. Now the report generation service is experiencing heavy load. We can of course put the service behind a load balancer but every autoscaling group has a maximum number of instances and a warmup time which limits its scale and its responsiveness to sudden spikes of traffic. If, on the other hand, we use a queue then the scale is practically infinite. Sure, it might take a long time to go through all the requests but we’re guaranteed that they’ll all be processed.
Reliability (and priority queues)
Then there’s reliability. When our report generation service goes down (and it will), or there’s a network glitch (and you know that’ll happen), synchronous messages will be lost after a certain timeout. For asynchronous we have retries and a dead letter queue. We could take the report generation service down for maintenance and we’d still be assured that all messages will be processed. Those that aren’t will be in the dead letter queue to be examined and replayed if necessary.
Another benefit we get from using queues is that we can prioritize requests. If the same service processes product views and purchase requests we can give the latter priority. If the service is under heavy load we can serve the product views slowly, perhaps even dropping some, while making sure that the purchase requests are not impacted by load.
Testability
Using queues the only thing we need to test separate microservices is to feed the messages to the queue and test that the consuming service behaves as expected. This is called consumer-driven contract testing. There’s no need to setup the whole service mesh in order to test. All we need is a queue, a message generator, and the service under test. This helps us find and localize bugs easily. It also simplifies testing and allows us to feed in lots of different variations of messages, which enables us to test the service under a variety of scenarios.
Devability
Yeah, I made that word up. When developing a monolithic application it’s reasonable to expect the whole application to run on a developer’s computer. But what if the application is made up of five (or fifty) services? What if some of them are serverless, like Kinesis or Lambda?
The answer, you guessed it, is asynchronous. Now all the developer has to do, just as in testing, is to run the service he’s working on, a queue, and a message generating component. No need to run the whole stack.
Cons
I’m not going to lie. Using asynchronous does add complexity. Instead of sending a message and waiting for a reply you must send a message, listen to a reply queue, and route the message to the sending client based on a message ID. The good news is that this pattern is common enough that many message brokers support it. Here, for example, is the RabbitMQ documentation on how to do it, complete with code in several languages.
The other thing is that by using asynchronous communication, and adding a queue between components, we’re necessarily adding some latency. Instead of communicating directly we’re adding two hops in each direction, one from the sending service to the queue and another from the queue to the receiving service. The good news is that if you pick the right queue that latency can be very small. This benchmark, for example, has RabbitMQ latency at O(1ms).
Summary
In this article I showed why asynchronous communication is the way to go in a microservices architecture. It’s more convenient for testing and development, makes deployment easier and is more reliable and scalable.
Did you find this interesting?Share it with others:
Did you find this interesting? Share it with others:
Meet Dex: the autonomous IT engineer that eliminates tickets before they appear
SysAid’s AI Agent Center: Command and control for your AI Agents

How SysAid manages agents behind restricted firewall rules with AWS IoT Core



